MCP? It's APIs All the Way Down

The emergence and rapid adoption of the Model Context Protocol (MCP) is already reshaping how developers think about integration, automation, and AI-driven systems. It seems like every other company (including WireMock) is announcing its own MCP server implementation, as are countless hobbyists and open source developers.
Obviously, we are still in the early days of this trend, and right now everyone is mostly in a race to get to market as quickly as possible – with considerations of quality, performance and security temporarily put to one side. However, as MCP servers start to be deployed into real production systems, particularly in the enterprise , tackling these problems will become a hard requirement.
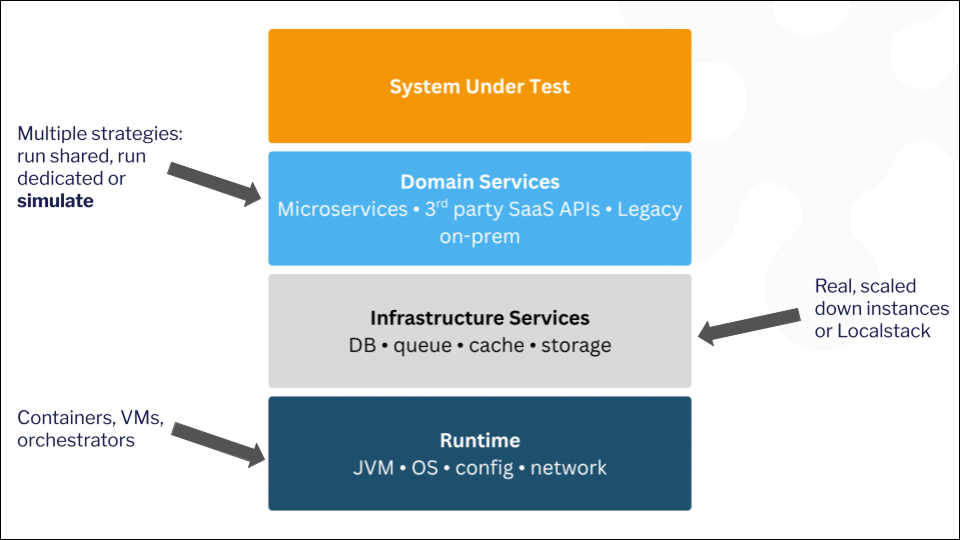
At that point, many teams building MCP-based integrations will run into the known challenges of developing software in closely coupled, integration-heavy environments with multiple API dependencies. API simulation, which allows teams to decouple their development and testing environments from production APIs and unreliable sandboxes, will be essential to maintain velocity and quality.
It’s APIs all the way down
MCP introduces a powerful abstraction layer between LLMs (large language models) and the real-world APIs they interact with. The agent receives a prompt, interprets context, and eventually (downstream) calls APIs to fetch data or perform actions. While the model feels autonomous, it still relies entirely on external APIs to drive actual functionality.
For example, let’s take this Google Maps MCP server. Once installed, it will give an agent access to various tools that rely on Google Maps - such as maps_geocode to convert coordinates to an address, or maps_search_places to find a place in Google Maps using text search.

When the user makes a mapping-related request, the AI agent will have these tools at its disposal and will not need to “figure out” how to write or execute an API call. However, the data itself is still retrieved via API, with the relevant calls executed by the MCP server.

These API calls might be invisible to the user, but they have essentially been hard-coded by however developed the MCP integration. In a sense, this is the main selling point of MCP in the first place - having all this mundane API work done so that the AI tool can more easily interface with external services and data.
The problem with API dependencies
Of course, the theoretical example above is very simple, and probably wouldn’t cause too many challenges for developers. But in practice, agents might have access to many different MCP servers, and a single MCP server might interface with multiple APIs or even multiple services. What happens then?
The answer is that teams run into a familiar set of problems, which they would generally solve using an API simulation tool like WireMock Cloud:
- Integration with 3rd party APIs that might not be available - e.g., financial APIs that are not always easy to access, or might incur costs per API call
- Sandboxes that don’t offer a reliable way to test complex workflows - such as end-to-end integration testing, load testing, or negative testing
- The MCP server might require access to an API which is not yet implemented (e.g., since it is being built by another team), which causes teams to sit idle
- Difficulty in isolating specific components of the MCP server or agentic workflows for testing purposes (did the test fail because of a problem with the server, or one of the APIs it depends on?)
These problems could affect the team developing an MCP server, as well as a team that’s using an MCP-based agent. And as mentioned, they are not new problems, and in fact they are similar to the ones that teams are currently facing when they’re developing software in integration-heavy environments.
However, as MCP use increases and companies look to use more integrations and more agent-based tools, the volume of API usage is likely to grow dramatically - along with all the challenges that come with it.
To develop MCP-based tools, look to decouple from dependencies
So we’ve seen that MCP doesn’t replace traditional APIs like REST or GraphQL since they are still running under the hood; and it doesn’t make API dependency problems go away, since these integrations are still implemented as code that needs to be written, tested and debugged like any other application code.
Are companies ready for the potential explosion in API consumption that MCP adoption is likely to introduce? My impression is that developers are currently focusing on getting as much value as they can out of MCP integrations and AI agents, as fast as they can, and are leaving the operational headaches for later. This is reminiscent of the rush to microservices, which promised modularity and speed - expectations that often crashed against the wall of dependency hell. Integration became a nightmare, testing grew slower, and local development became increasingly painful.
How can you prevent similar problems from slowing down your MCP development? Well, as the CEO of WireMock I have a biased take - which is that the best way to decouple from API dependencies during development and testing is to have scalable, reliable, and enterprise-grade API simulation in place.
The challenges that have made WireMock so popular - both in the open source edition and our cloud enterprise platform - are more urgent than ever: working with a wide range of 3rd-party APIs, simulating complex flows, and enabling parallel development based on API prototypes. However, the stakes will be higher than ever, as the success of AI-powered development will now depend on it.
For teams to get value out of AI agents, they have to be able to understand and test their impact without constantly rushing to debug a failed API integration. This means they will need robust API simulation platforms that can:
- Handle stateful, multi-step scenarios.
- Support dynamic behavior and chaining of mock logic
- Align with OpenAPI specs and real-time schema changes
- Emulate production-like latency, error cases, and load conditions
- Support multiple protocols such as gRPC and GraphQL (rather than just REST)
API mocking and simulation will be a foundational layer for building and scaling MCP systems. And the teams that invest in realistic, scalable mocking infrastructure now will be the ones best equipped to lead in the world of AI-native architectures.

/
Latest posts

Have More Questions?

.svg)
.png)

.svg)